


There is nothing more satisfying than sitting back after a hard day’s work and admiring the masterpiece before you.
The Mona Lisa of clean code.
You start envisioning great monuments being erected in your honor, temples being built and systems named after you. You’ve done it, you’ve written perfection.

You begin crafting your PR to showcase this masterpiece to your team.
As you are about to submit, you hear a slack notification ring on all 8 of your devices in unison. Someone must have already seen your commit, the praise is already flowing in.
Hey I need you to change the code so it also checks XYZ
Not what you expected, but it’s OK. Your code is so clean, readable, modular, composeable and maintainable that adding a new check should be an absolute breeze.
You open up VIM (because you’re not a peasant) and begin scanning, trying to find the right place to slot this new piece of logic.
Then it hits you.

There’s nowhere you can easily add it.
Everything is so tightly coupled it’s one ant’s breath away from collapsing. Adding another function would require a complete refactor.
What you thought was a bunch of high-quality Lego bricks is more like a Jenga tower in the hands of a toddler throwing a tantrum.
What is clean code?
Dramatic scenes aside, this is a common problem that ALL developers suffer from at one point or another (the code part, not the god-like complex I hope).
Writing clean code isn’t easy. People are lying if they ever tell you that. It takes meticulous planning and very deliberate choices.
I’m definitely no expert on writing clean code, I’ve even been known to dabble in the art of crafting monstrosities, but hopefully I can share a thing or two which will help make your code just that little bit nicer and more manageable.
Now this post isn’t going to go through what clean code is as there are a 1000 and 1 other articles out there that do that, such as:
You get the picture.
Writing clean code comes down to three things:
- Readability
- Maintainability
- Testability
We don’t write clean code for the sake of writing clean code, we write clean code because it allows us and others to iterate on a project efficiently and effectively.
(well that’s not the only reason but one of the main ones IMHO)
How can we write clean elixir code?

Elixir being a semi-functional programming language already has a lot of clean code features built-in.
One of these features is immutability.
Immutability restricts developers from changing or modify existing data structures.
Instead, if you want to change a value, you must first copy the value and then modify it.
This means that you can be sure that what you see at any point in the code is going to be exactly what you expect. No other random class or function is going to have modified that value under your feet. This makes it so much easier to reason about your code and as a direct result makes your code cleaner.

But using a functional language doesn’t automatically make your code and cleaner than using a non-functional language. It’s just as easy to write extremely dirty code using elixir as it is in Ruby or Java.
Layers to the rescue
The one concept that I feel helps beginners write clean, functional code was the concept of ports and adapters/hexagonal/onion layering done right (it goes by other names as well).
If you haven’t already then I strongly recommend that you check out this video before progressing: Functional Architecture - The pits of success from Mark Seamann.
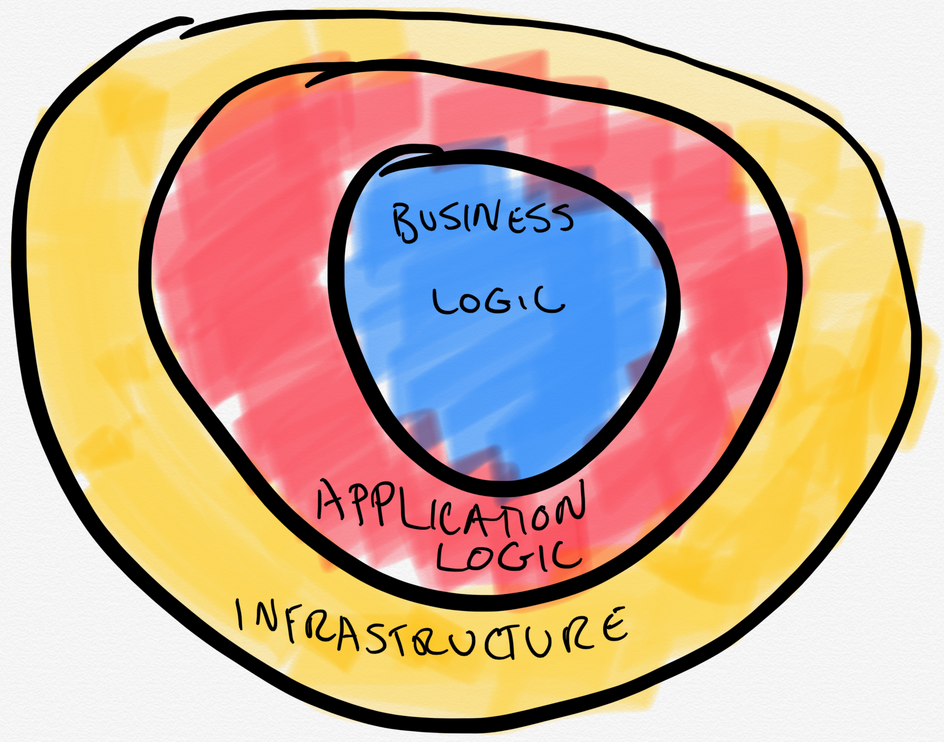
The basic idea though is that you separate the application into different layers/sections. If you want to use hexagonal architecture language, you connect the infrastructure layers with the pure business logic layers via the use of ports and adapters.

Business Logic
Our innermost layer is our business logic layer. Here is where we put all the functions that relate to our domain. For example, Repo.get/2 is not a domain function but rather an implementation choice within our domain.
A domain function might instead be user_is_able_to_purchase/1 which IS a domain function. A good way to check between the two is to think about whether or not you could change the implementation of that function and if so, would it still solve your problem.
For example, given the above:
Repo.get/2 could instead be changed to 'users.csv' |> CSV.read!() |> Map.get(user_id). Does our domain still function with this change? Yes. We have just changed how our users are stored, it does not affect whether or not our domain functions, it’s just an implementation detail.
On the other hand, if we changed user_is_able_to_purchase/1 from checking the age of the user, to let’s say, checking the shoe size of the user, then NO in this case, our domain would not still function correctly, because it is a requirement of our domain to ensure that users are over 25.
All functions within this layer should ideally be pure. All impure functions are typically not core business logic functions and as a result, should be pushed to the outer layers. This layer should have no dependencies as put very aptly by Scott Wlaschin
All dependencies must point inwards
Application Logic
The next layer can either be a single layer or multiple layers. The outer layers are where all your infrastructure or implementation details live. I like to break it up where the inner-outer layer is typically your application logic layer, where you essentially take these pure business logic functions, and compose them into services or interweave the data between the three layers. I like to think of this layer more of as an Orchestrating layer - directing the flow of data. Ideally, these should be pure as well but not always the case.
An example of this type of function might be a function that validates the params coming in from a rest endpoint.
Infrastructure Code
The outer most layer is where we keep our infrastructure logic. Typically the outer most layer is going to be the most impure. Here we will encapsulate the infrastructure, web layer, database layer, network interfaces, etc. These typically combine a lot of services to build out an implementation.
These are typically functions that deal with things like handling web requests, saving data to the database, etc.
TLDR: Separate your business logic from your implementation details.
Benefits
It’s easier to distinguish between the business logic, and the implementation logic within a function. This means that it is also easier to understand which means that it’s easier for people to change and as a result can more easily verify their changes are correct.
- Distinguish + Understand = Easier to read (readability)
- Change = Easier to maintain (maintainability)
- Verify = Easier to test (testability)
Examples
Now it’s time to write some clean code using the above architecture pattern. Now the following code is going to be extremely poor for exaggerating purposes to make it easier to identify what dirty code looks like and how we can refactor it.
OK so to start with, let’s assume you are tasked with the following:
Create a register_user function which takes a set of user prams, and returns a newly created user or an error.
Logically the function also needs to:
- Validate the incoming params have all the required fields
- Verify the organization the user is added to has enough seats/licenses for the user to be registered
- The user needs to be added to the organizations
- If the user is successfully registered, then a welcome email should be sent.
So first, let’s take the most naive approach and a clear example of what dirty or non-clean code looks like.
Seriously, this is bad, prepare yourself.
1def register_user(%{organisation_id: org_id, account_type: type}} = user_params) do2 case Enum.all?(["name", "email", "password", "organisation_id"], fn(field) -> user_params[field] end) do3 true ->4 case Repo.get(Organisation, org_id) do5 nil -> {:error, :not_found}6 org ->7 valid =8 case type do9 "basic" -> org.used + 1 > org.capacity10 "pro" -> org.used + 2 > org.capacity11 "elite" ->12 if org.grandfathered do13 org.used + 1 > org.capacity14 else15 org.used + 3 > org.capacity16 end17 end1819 if valid do20 %User21 |> User.changeset(user_params, organisation)22 |> Repo.insert()23 |> case do24 {:ok, %User{} = user} ->25 case EmailLibary.send("Welcome to OurCompany", user.to, "hello@xyz.com") do26 :ok -> {:ok, user}27 error -> error28 end29 error -> error30 end31 else32 {:error, :over_capacity}33 end34 end35 false -> :error36 end37end

OK now obviously this isn’t something you would frequently see, but an exaggerated example to highlight the issues of dirty code.
So looking at this function, we can see it meets all the acceptance criteria.
- ✅ It validates the Params
- ✅ Verifies the organization’s seat capacity
- ✅ Saves the user under the organization
- ✅ Sends a welcome email
If this post was about writing code that met the product requirements, we’d be done right here and now.
But it’s not, it’s about writing clean code and this poor summer child has strayed far from the light.
So let’s break down exactly what’s wrong with code and why it would not be considered “clean”. To do this, we will use the three elements of clean code that I listed above. Again, there are a lot more benefits/characteristics of clean code but for now, let’s just focus on these three.
- Readability:
Nope.
An experienced programmer (or even a novice) could probably read through this function and determine what it is doing given enough time. You can vaguely go through and get an understanding of what’s going on here but an important aspect is missing. You are not sure why things are being done the way they are.
Why do they go through the ["email", "name"..] params? Why do they do that weird valid check thing with the capacity?
By reading this code, I have no idea what is happening.
Because I have no idea what is going on or WHY things are done the way they are, I do not feel confident in making changes to this code.
- Maintainability:
Good luck.
- Testability:
Tests are a great way to determine if your code is doing more then it should.
If you are writing unit tests to validate XYZ but also have to set up ABC then you need to think if what you are testing is well thought out.
Think about how you would go about testing all the logic in this function. If you wanted to test the email sending logic, you’d first need to set up a user and organization in the db, build the rights params and ensure the org is valid all to just test that the sending of an email is valid?!
The problem with this being untestable isn’t just it’s a nightmare to test, its that because it’s a nightmare that devs won’t want to test it or at the very least only test small parts of it, possibly leaving large crucial parts untested, because really, who wants to test the above monstrosity.
So in summary:
- ❌ Is not readable
- ❌ Is not understandable
- ❌ Difficult to maintain
- ❌ Hard to test
So how can we fix it?
First let’s break this code apart and try and separate our business logic, application logic and our infrastructure code.
1case Enum.all?(["name", "email", "password", "organisation_id"], fn(field) -> user_params[field] end) do2 true -> #....3 false -> :error4end
This isn’t business logic, this code is needed as a consequence of the implementation we went with. What’s nice though is that this is pure, which means it’s going to be super easy to test. So let’s move this to the outer layers.
1case Repo.get(Organisation, org_id) do2 nil -> {:error, :not_found}3 org -> #....4end
Impure + database access = outer layers
1valid =2 case type do3 "basic" -> org.used + 1 > org.capacity4 "pro" -> org.used + 2 > org.capacity5 "elite" ->6 if org.grandfathered do7 org.used + 1 > org.capacity8 else9 org.used + 3 > org.capacity10 end11 end
Checking if an organization has enough seats left? This one is business logic. Without this code, our application would not solve the problems of our business domain.
1%User2|> User.changeset(user_params, organisation)3|> Repo.insert()4|> case do5 {:ok, %User{} = user} ->6 case EmailLibary.send("Welcome to OurCompany", user.to, "hello@xyz.com") do7 :ok -> {:ok, user}8 error -> error9 end10 error -> error11end
Database inserting + sending emails = Impure = Outer layers
Refactoring
OK so now it’s time to refactor.
What elixir goodies do we have at our disposable to clean this up?
- Modules: Separate the concerns
- Functions: Maybe having everything in a single function isn’t the best of ideas
with: Allows us to do railway oriented programming@spec: Provides a basic level of type checking, but more importantly improves readability- Naming: Can be improved
So how could we refactor the above using these tools?
So firstly, let’s pull out the params validation logic:
1# user_params_validator.ex23defmodule UserParamsValidator do4 @valid_params ~w(name email password organisation_id)56 @moduledoc """7 #...8 """910 @spec valid?(Users.user_params()) :: {:ok, :valid} | {:error, :invalid_params}11 def valid?(user_params) do12 case Enum.all?(@valid_params, &(user_params[&1]) do13 true -> {:ok, :valid}14 false -> {:error, :invalid}15 end16 end17end
So now we have a super simple module that takes a set of params and returns a boolean if they are valid or not.
Looking at this module it’s easier to tell what it does. Not only that it’s super simple to test. No complex setup required, no databases needed, nothing. Just feed it a set of params and ensure they are valid.
Next, let’s extract the business logic out into its own module as well and tidy it up a bit.
1# oragnisations/capacity.ex2defmodule Organisation.Capacity do34 @spec check(Organisation.t) :: :ok | {:error, :over_capacity}5 def check(%Organisation{capacity: cap, used: used, grandfathered: grandfathered}, acc_type) do6 acc_type7 |> account_type_to_capacity_modifier(grandfathered)8 |> over_capacity?(cap, used)9 |> case do10 true -> :ok11 false -> {:error, :over_capacity}12 end13 end1415 @spec account_type_to_capacity_modifier(String.t, boolean) :: integer()16 def account_type_to_capacity_modifier("basic", _), do: 117 def account_type_to_capacity_modifier("pro", _), do: 218 def account_type_to_capacity_modifier("elite", true), do: 1 # Grandfathered elite accounts only count for 1 extra seat19 def account_type_to_capacity_modifier("elite", false), do: 22021 def over_capacity(new_seats, used, capacity) when used + new_seats <= capacity, do: :ok22 def over_capacity(_, _, _), do: {:error, :over_capacity}23end
Before we had a complex expression that at first glance applied some unknown logic to determine whether or not the type of the organization was valid. Reading it, we had no idea what the actual business logic/reasoning behind the implementation was. We could probably figure it out given enough time but that doesn’t always mean we understand it.
Now that it’s split out into a module named Organisations.Capacity with a root-level function named has_enough_seats? and a type spec returning an error value of {:error, :over_capacity}, we can have a pretty good idea of what this module/function is doing, without having to think too hard or consult some out of date ticket.
As we have broken the algorithm into human-readable steps, we can read this like a story:
- First, we take the account type and turn it into some sort of modifier
- Next, we use that modifier along with the total capacity and remaining capacity to check whether or not adding this user would go over the companies capacity limits
- If it’s valid then return
:ok - Otherwise, return a relevant error message (I don’t like returning booleans because then meaning needs to be interpreted at the calling site)
At a high level, we now have a pretty good understanding of what this function does, digging even deeper we can see that there’s a comment explaining to us that legacy or grandfathered accounts have a lower count modifier then normal elite accounts.
I think this it’s important to point out here that the quote “your code should be self-documenting” isn’t always possible. Sometimes comments ARE needed. Sometimes no matter how clean your code is there is going to be some business decision that you need to explain with a comment that your code can’t and that’s OK.
Again this module now is super easy to test, we simply pass the function an %Organsiation{} struct (does not have to be inserted into a DB) with some pre-built state and test our assumptions.
Next, we do the same with the email sending:
1# emails.ex2defmodule Emails do34 @spec send_welcome_email(User.t) :: :ok | {:error, any()}5 def send_welcome_email(user) do6 case EmailLibary.send("Welcome to XYZ", user.to, "hello@xyz.com") do7 {:ok, _resp} -> :ok8 {:error, reason} = error -> error9 end10 end11end
Same idea as the functions above - extract into an isolated module, add specs and improve naming.
Last up is the Users module which ties all these functions together:
1# users.ex2defmodule Users do3 @type user_params :: #....45 @spec register_user(user_params()) :: {:ok, User.t()} | {:error, any()}6 def register_user(user_params) do7 with {:ok, _} <- UserParamsValidator.validate(user_params),8 {:ok, org} <- Organisations.get(user_params.org_id),9 :ok <- OrganisationCapacity.check(org, user_params.type)10 {:ok, user} <- insert_user(user_params, org),11 :ok <- Emails.send_welcome_email(user)12 do: {:ok, user}13 end1415 def insert_user(user_params) do16 %User{}17 |> User.changeset(user_params)18 |> Repo.insert()19 end20end
Here we are using the with operator as a way to achieve railway-oriented programming and avoid the pyramid of doom we had above.
Railway-oriented programming allows us to decouple the return value of one function as the input to another, which makes composing functions much easier.
E.g. if we were instead to pipe this all through a single pipe chain:
1user_params2|> UserParamsValidator.validate()3|> Organisations.get()4|> OrganisationCapacity.check(user_params)5|> insert_user(user_params)6|> Emails.send_welcome_email()
Think about what each function would need to return to cater to the input requirements of the next function. Now think about trying to use those functions in any other use-case. Pretty hard right?
When you try and force pipe chains on a use-case where pipe-chains aren’t the solution you are going to end up with a tightly coupled mess that is going to be a pain to maintain and defeats any chance of composability.
A general rule I like to use is that pipe chains are best for dealing with pure transformations on a single data structure (e.g. a set of transformations on a list). When you come to more complex examples, then other tools are going to be better.
So back to the function, now we are simply calling each of these functions and ensuring we only proceed if the previous function returned an expected value. Technically, we can now compose these functions in any order we wanted and the function as a whole should still work (obviously it wouldn’t make sense to do this though) which indicates that these functions are highly composable.
But there is still one last problem. The register_user function depends on some of our outer layers (Organisations.get/1, insert_user/2, send_email/1) , whereas initially, we said we were going to have dependencies only point inwards. This means that this function is now directly coupled to an external dependency which isn’t what we want. If we wanted to change it so that some users get an email or some users get a text message, we would have to apply some logic within in this function to determine that or if we changed the inputs/return values of the Email send function would require us having to potentially make changes to the implementation of this function (which then might also have a ripple onto other functions).
It also means that to test this function, even at a unit level, we need to have the database setup, the email client running, etc. which adds more noise and makes testing more difficult.
There are two ways we can remove this dependency.
The first way is to use dependency inversion which we can achieve by creating behaviors in elixir to define a contract that modules must conform to.
OR
We can use dependency injection, where we inject these functions at run time as arguments to the function. I prefer to use injection just because I think it reads better and is less boiler-platey but both are valid approaches. If you want to have a look at a dependency inversion example, Jose Valim wrote an article about using mocks through explicit contracts
So how would this look?
1defmodule Users do2 @get_org :: (String.t() -> {:ok, Organisation.t()} | {:error, atom()})3 @insert_user :: (map(), Organisation.t() -> {:ok, User.t()} | {:error, atom()})4 @send_welcome :: (User.t() -> :ok | {:error, String.t()})56 @spec register_user(user_params(), get_org(), insert_user(), send_welcome()) :: {:ok, User.t()} | {:error, any()}7 def register_user(user_params, get_organisation, insert_user, send_welcome_email) do8 with {:ok, _} <- UserParamsValidator.validate(user_params),9 {:ok, org} <- get_organisation.(user_params.org_id),10 :ok <- OrganisationCapacity.check(org, user_params.type)11 {:ok, user} <- insert_user.(user_params, org),12 :ok <- send_welcome_email.(user)13 do: {:ok, user}14 end15end
So what’s changed? Firstly we’ve created a few new types that show the types of the functions that this function accepts. This isn’t for compiler time guarantees per se, but more for readability - it shows the reader what these functions accept and the return values of these functions.
Next, we change this function to take in 3 extra variables, which are each a function passed in at runtime which performs a certain action that was previously called inline.
So before, we would have called this function as:
Users.register_user(params)
Now we call it like:
Users.register_user(params, &Organisations.get/1, &Users.insert_user/2, &Emails.send_welcome_email/1)
So why did we do this? What are the benefits?
- We can now test this function super easily at a unit level:
1describe "register_user/4" do2 #...34 test "returns an error if the organization can't be found" do5 params = %{} # valid params6 get_org = fn _ -> {:error, :org_not_found} end7 assert {:error, :org_not_found} == Users.register_user(params, get_org, &(&1), &(&1)) # Use identity functinos for the last two because they won't be called8 end9end
No need for a database, no need to set up a certain state of the world - just pass a function that returns a possible value and assesses whether or not the function behaves correctly. This allows us to test the expected behavior rather than the implementation details of the function. We don’t necessarily really care where the org comes from, as long as one is returned. Fetching it from the database is one way to get it, but not the only way.
It’s still a good idea to have one or two integration tests where you might use the real functions, but the benefit here is that they can focus on the happy/basic cases rather than having to test the minute edge cases that normally occur in unit testing.
- We have increased flexibility:
We can now have the caller pass different functions at run time rather than relying on a single function always being called. E.g. we can pass a function to send a text message or a function to send an email. If at the calling site, we already know the organization, we might instead pass an anonymous function which returns just that (e.g. fn _ -> {:ok, org} end).
- We have increased purity:
This function is now pretty close to being pure, depending on the functions passed in which has all the added benefits - easier testing, readability, refactoring, etc.
On the downside, it is now a bit more verbose to call this function. However, we do have two ways to solve this:
- Use default values for each org:
register_user(user_params, get_org \\ &Organisations.get/1, ...)etc. - Use partial application:
1#...inside some func2register_user_with_email = fn(params) ->3 Users.register_user(params, &Organisations.get/1, &Users.insert_user/2, &Emails.send_welcome_email/1)4end56#..logic78register_user_with_email.(params)
And there we go! We should now have a much “cleaner” piece of code then what we started with.
This turned out much longer then I expected to say the least, but I hope it was helpful in some way or another.
If you have any questions or comments feel free to leave them below (or if you disagree with anything I’ve said) and I’ll reply to them as soon as possible.


